Leader-Based Multi-Scale Attention Deep Architecture for Person Re-Identification
|
Fudan University, China University of Surrey, United Kingdom
|
Abstract
|
Person re-identification (re-id) aims to match people across non-overlapping camera views in a public space.
This is a challenging problem because the people captured in surveillance videos often wear similar clothing. Consequently, the differences
in their appearance are typically subtle and only detectable at particular locations and scales. In this paper, we propose a deep re-id
network (MuDeep) that is composed of two novel types of layers – a multi-scale deep learning layer, and a leader-based attention learning
layer. Specifically, the former learns deep discriminative feature representations at different scales, while the latter utilizes the
information from multiple scales to lead and determine the optimal weightings for each scale. The importance of different spatial locations
for extracting discriminative features is learned explicitly via our leader-based attention learning layer. Extensive experiments
are carried out to demonstrate that the proposed MuDeep outperforms the state-of-the-art on a number of benchmarks and has a better
generalization ability under a domain generalization setting.
|
Motivation
|
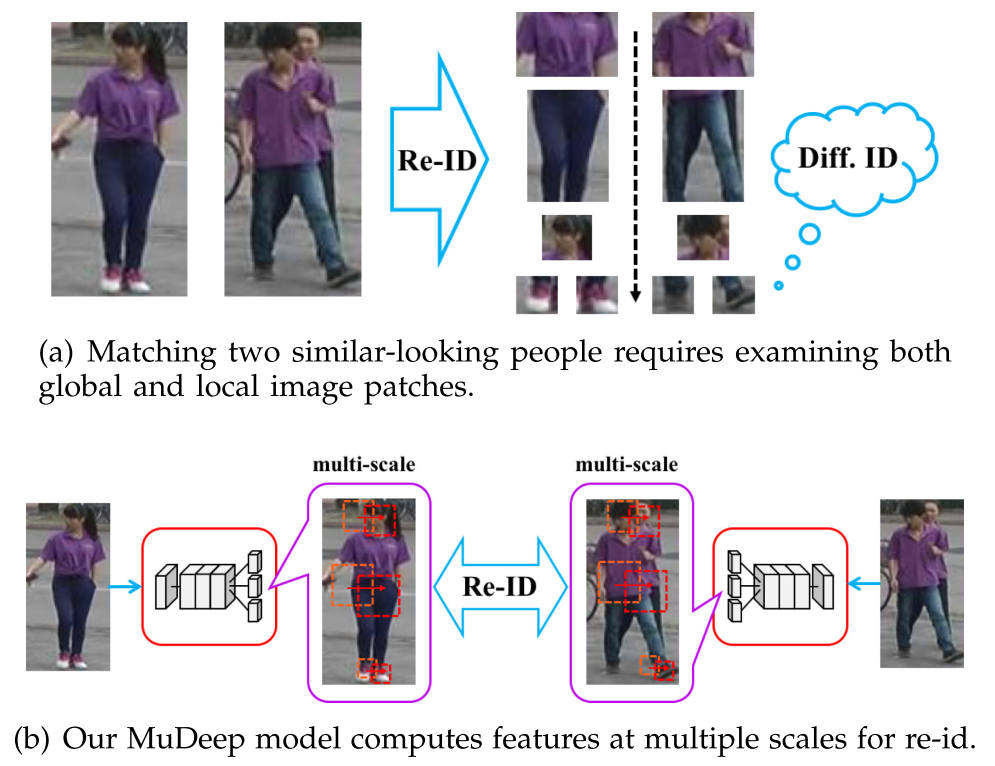
Computing multi-scale features is crucial for re-id and motivates our approach.
In (a), to distinguish between two people wearing similar clothing, global visual cues such as body shape and
clothing color are insufficient. Visual cues from local parts such as shoes and hairstyle are needed for telling
them apart. Motivated by this observation, our MuDeep, as shown in (b), learns discriminative features at different
spatial scales and locations (indicated by the red dashed boxes)
|
MuDeep
|
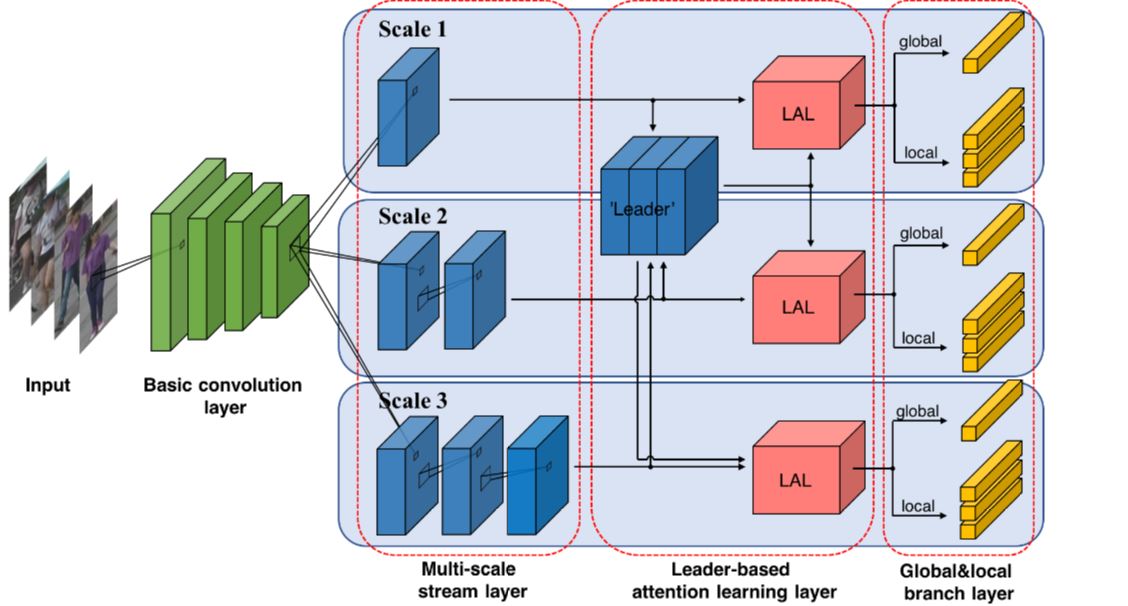
A novel multi-scale representation learning architecture is proposed for learning discriminative person
appearance features at multiple spatial scales and locations. Critically, the multiple scales refer to different resolution levels of
filters, rather than multiscale inputs. And a leader-based attention learning layer can utilize the information computed at all scales
to lead, and dynamically determines the important spatial locations in the feature extraction at each scale.
|
|
The multi-scale stream layer first analyzes feature maps with multiple scales. Then the leader-based
attention learning layer is followed to automatically discover and emphasize important spatial locations. Finally, the global and
local branch layer is utilized to extract discriminate features from global and local parts. Note that the parameters of each
scale are not shared. ‘LAL’ means the Leader-based Attention Learning layer.
|
Paper and code

|
Leader-Based Multi-Scale Attention Deep Architecture for Person Re-Identification
Xuelin Qian*, Yanwei Fu*, Tao Xiang, Yu-Gang Jiang, Xiangyang Xue
[Paper]
[Bibtex]
[GitHub]
|
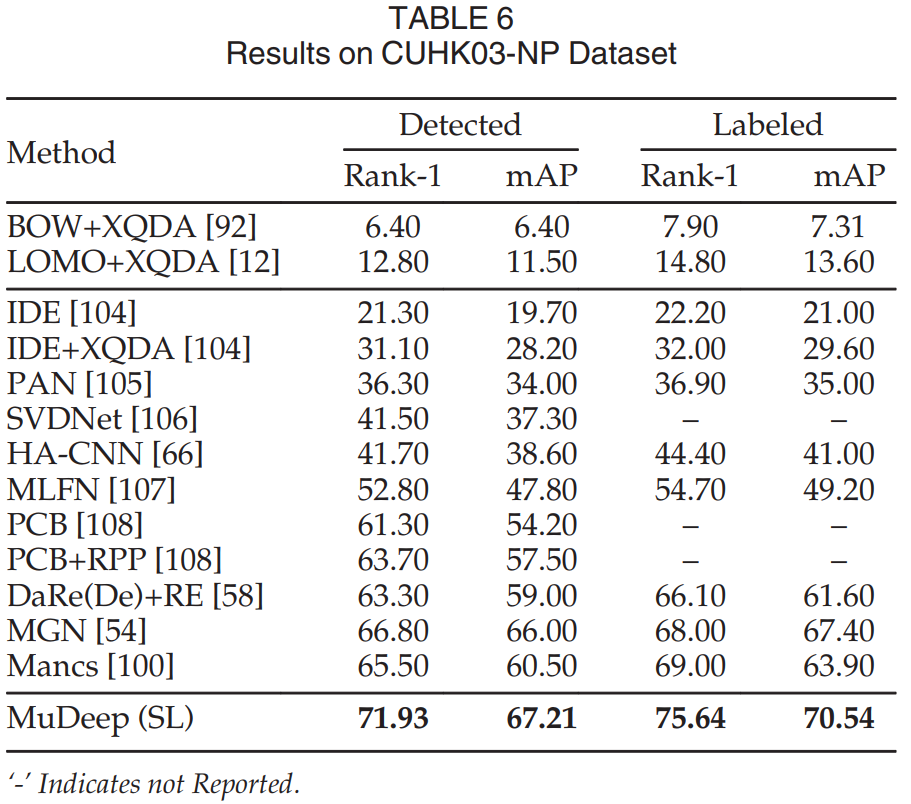
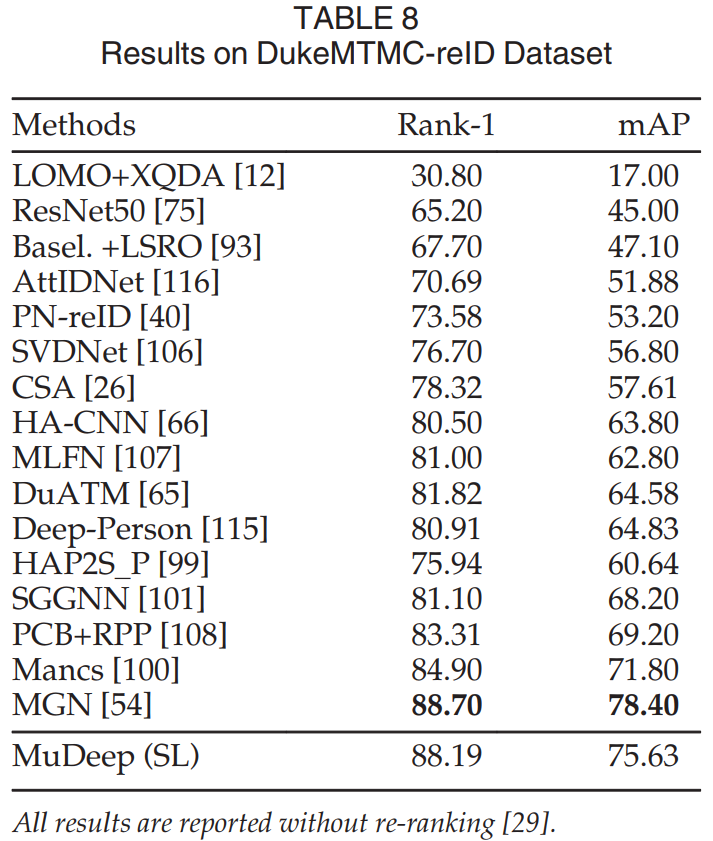
Results
|
Acknowledgements
The website is modified from this template.
|